
搜索视频
 相关视频、频道和播放列表
相关视频、频道和播放列表- 每次查询最多 700 个结果
- 实时和批处理
Collect and analyze YouTube comment data at scale—from raw content to engagement metrics—with precision control and high-throughput performance.
大规模查找、验证、收集和丰富企业级多模态数据




我们的 AI 驱动的网络数据采集基础设施立即可用。
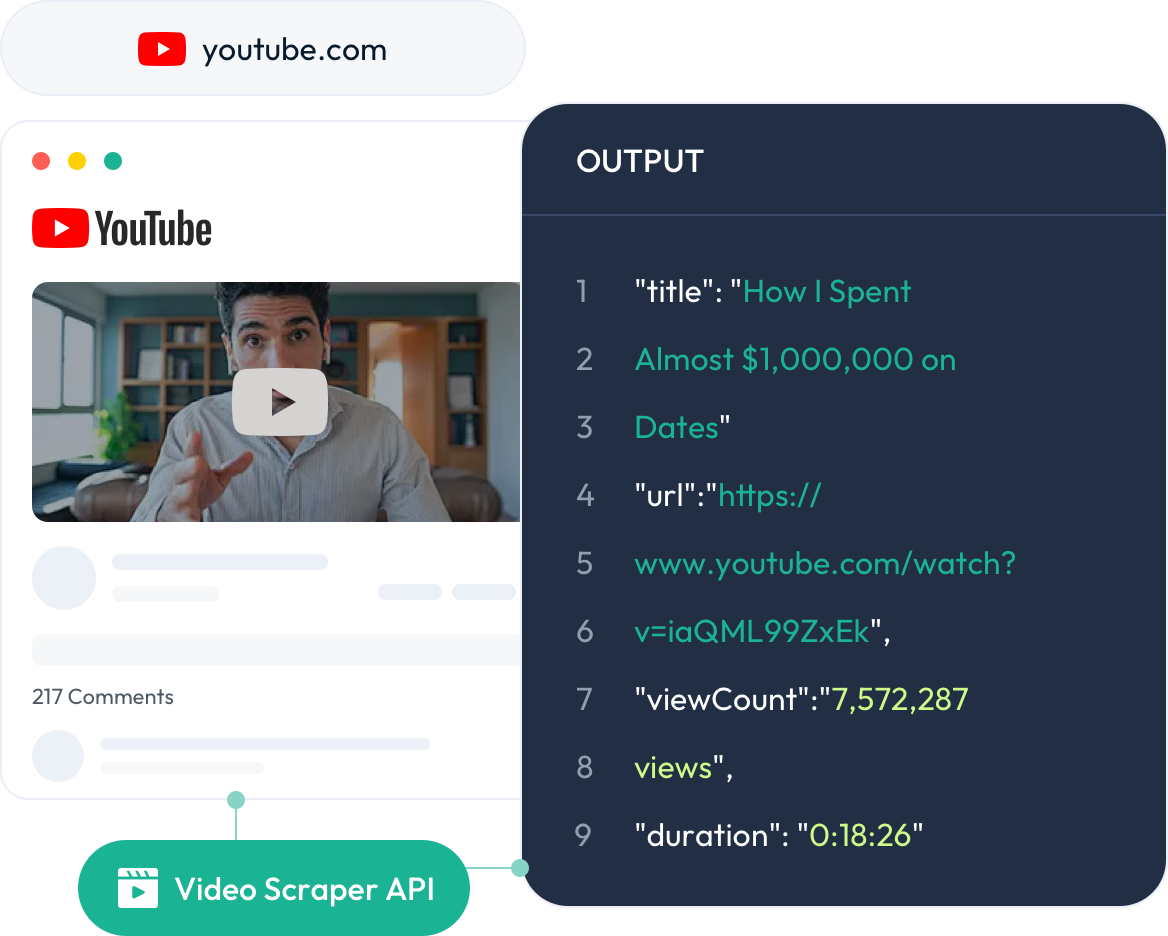
只需几个简单步骤即可获得清晰、结构化的 YouTube 数据。

 下载视频/音频内容
下载视频/音频内容 获取视频转录文本
获取视频转录文本提供带有 youtube_search 源的搜索查询以获取标准结果(最多 20 个结果),或使用 youtube_search_max 获取更全面的结果(最多 700 个结果)。根据需要应用过滤器,并以 JSON 格式获取结构化的搜索结果。
查看右侧的输出代码示例以了解响应格式。
{
"results": [
{
"content": [
{
"videoId": "jqSLxWlH_iY",
"title": "How to build better multimodal datasets",
"thumbnails": [
{
"url": "https://i.ytimg.com/vi/jqSLxWlH_iY/hqdefault.jpg"
}
],
"channelName": "Aproxy Labs",
"duration": "12:48"
}
]
}
]
}利用 Web Scraper API 的强大功能进行可扩展的视频数据提取
使用来自 195 个国家的高级代理池进行 ML 驱动的代理选择和轮换。
独特的 HTTP 头、JavaScript 和浏览器指纹确保对动态内容的弹性。
自动重试和 CAPTCHA 绕过,实现不间断的数据检索。
以所需频率自动执行重复的抓取任务,并将数据接收至您的云存储。
同时从多个页面提取数据,每批次最多 5,000 个 URL。
将数据获取到 Amazon S3、GCS、阿里云 OSS 和其他 S3 兼容存储,或通过 API 访问结果。
易于集成、自定义,并支持大量请求。
如有任何问题或疑问,获得专业支持。
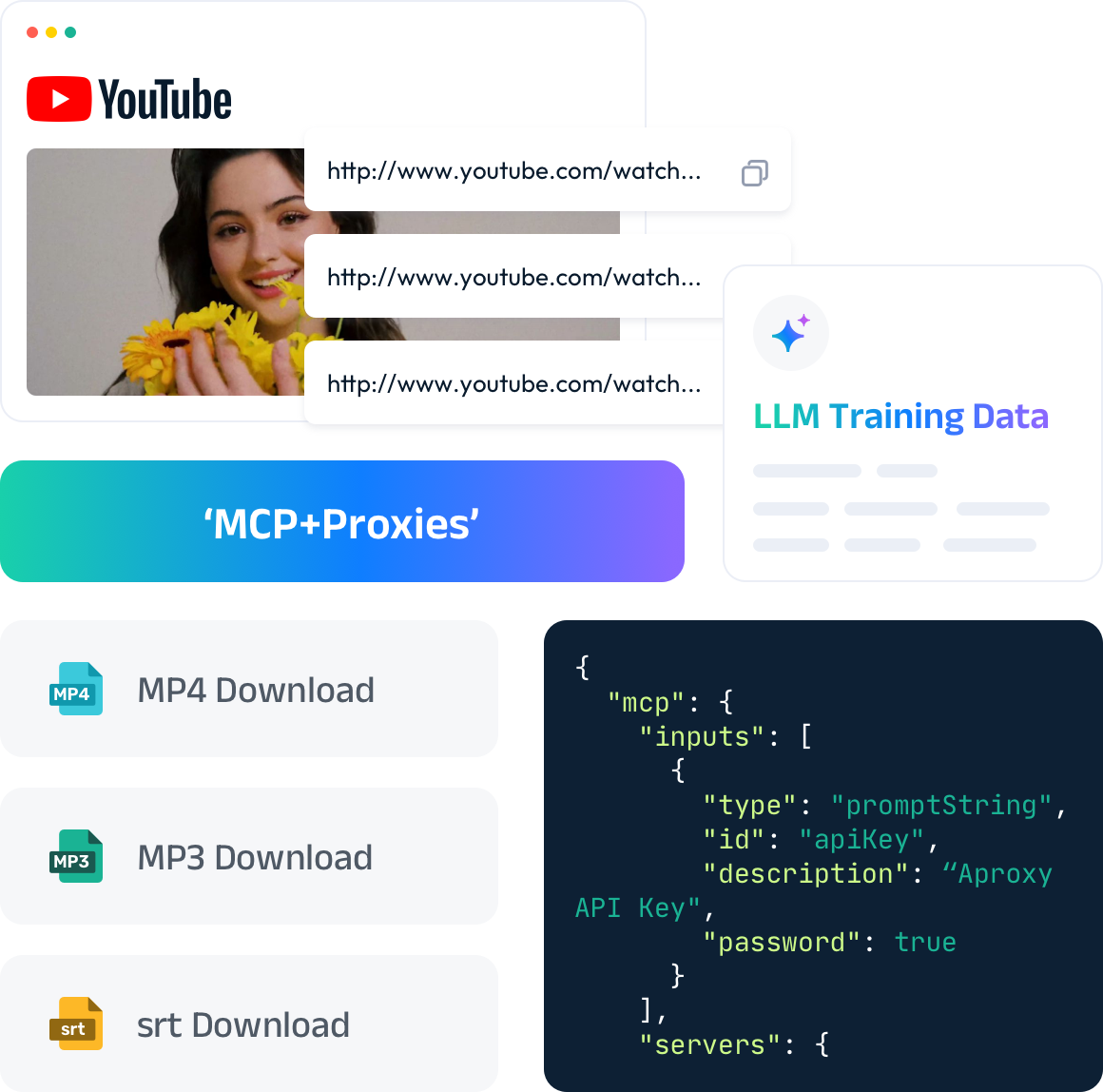
将 MCP 与我们的代理网络结合使用,绕过反机器人屏障,可靠地抓取视频平台,确保流畅的视频数据提取和下载。








